

 Digitization Department
Digitization DepartmentDWork – Heidelberg Digitization Workflow
http://dwork.uni-hd.de
The University Library of Heidelberg uses its in-house development DWork – Heidelberg Digitization Workflow to support the process flow of digitization and the web presentation of the digitized works.
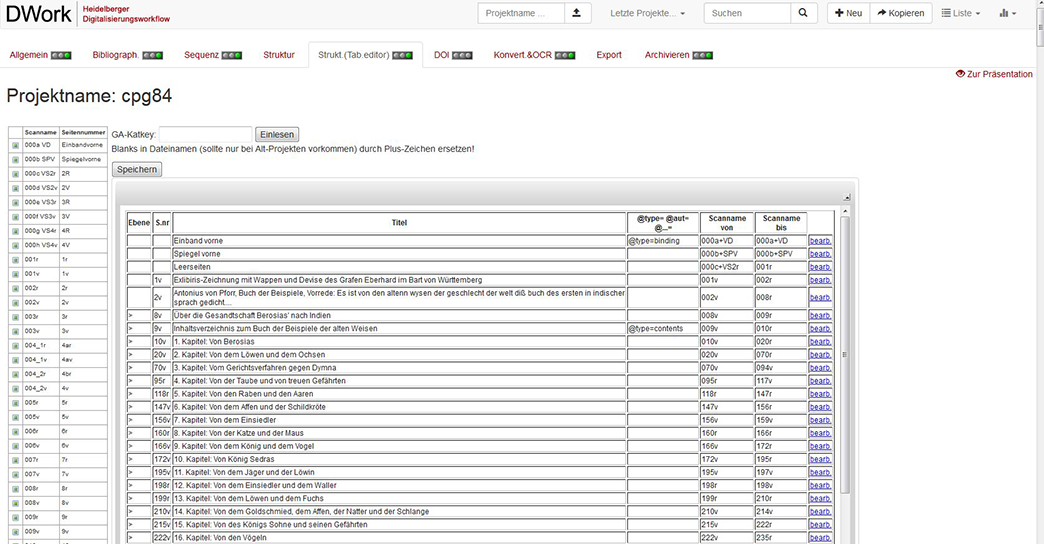
The software as a web application thereby supports all single steps of the workflow from the creation of metadata, scan processing (inclusively image converting and automatic text recognition) creation of the web presentation to the storage of scans and metadata.
The DWork concept aims to realise the guidelines provided by the Deutsche Forschungsgemeinschaft (DFG) and to develop an easy to operate and transparent user interface.
Modules and technical requirements
The technical basis of the software consists of the following modules:
- Digitization workflow
- Presentation
- Storage
- component for editions
- annotation tools
- authority file server (at planning stage)
Software is programmed in PERL. Further software requirements are:
- Webserver: Apache 2.x
- Database: MySQL 5.x
- Metadata and full-text search: SOLR
- Annotations module: https://github.com/kba/anno-common and https://github.com/kba/anno-frontend
- IIIF-Image-Server: Cantaloupe Image Server
- Editions module: eXistdb
Workflow
The singleworkflow steps (General - Bibliography - Sequence - Structure - Converting + OCR – Export - Storage) are selected by a file card system. The progress within the workflow is visualised by a traffic light system so that an overview is available at any time.
Viewer
We use SemToNotes to build our facsimile viewer and the SVG-Selector to select areas.
OCR-Converting
We use Abbyy Finereader for Linux for OCR converting.
For manual correction of the OCR texts we perform first tests with the software PoCoTo.